What did you accomplish today?


Re: What did you accomplish today?
I'm changing the format of my comprehensive Commonthroat grammar... again. It started as markdown, then I went to Word, and now it's back to markdown again. Pandoc has a method of rendering discontiguous numbered lists that can be used to number and cross-reference examples. Unfortunately it works great in HTML but not when I try to render it as a Word doc. Haven't tried mediawiki yet.


Re: What did you accomplish today?
I've finally dug into what I now termed the "language editor" for my diachronic conlanging app. Mostly setting up the basic GUI and structure of it, as well as making various design decisions in anticipation of intended features, but that's often one of the more exciting parts of programming.
Internally, a project will now be able to hold any number of languages. While I expect most people will only need one, leaving the door open for more means that users will be able to split off dialects or introduce borrowings and mergers internally, without having to import from other project files (unless they choose to).
In addition, I've set it up so that each language is stored under a (hopefully) unique and automatically generated ID, to prevent any accidental overwriting.
Internally, a project will now be able to hold any number of languages. While I expect most people will only need one, leaving the door open for more means that users will be able to split off dialects or introduce borrowings and mergers internally, without having to import from other project files (unless they choose to).
In addition, I've set it up so that each language is stored under a (hopefully) unique and automatically generated ID, to prevent any accidental overwriting.
DeviantArt | YouTube | Tumblr
-
eldin raigmore

- korean

- Posts: 6420
- Joined: 14 Aug 2010 19:38
- Location: SouthEast Michigan
Re: What did you accomplish today?
You can guarantee uniqueness by using a UTC timestamp plus a language-counter plus a code uniquely identifying the creator and/or the computer from which the creating was done. 32 bits probably won’t be enough to guarantee uniqueness, but I bet 128 will be. (If not, surely 256 bits will be enough?)
The time probably doesn’t need to be preciser than 1 second, but you might want to use .01 sec instead.
The language-counter probably can recycle itself every million (10^6) times, but you may prefer a billion (10^9) times.
I think at max that might use:
105 bits for time-created
32 bits for creator id
32 bits for computer id
30 bits for number of languages created in this centi-second
________.
199 bits.
That’s probably overkill.
——————.
I like the problems and solutions you come up with!
I will keep lurking!
My minicity is http://gonabebig1day.myminicity.com/xml
-
Khemehekis
- mongolian

- Posts: 4688
- Joined: 14 Aug 2010 09:36
- Location: California über alles
Re: What did you accomplish today?
I just finished the L-words from the IGCE list. From #102,001, dab ad enzes (labellum or lip, as of a flower, lit. "landing cup") to word #103,096, Tshabillat (Chabillat, a beach town in eastern Durben, created to offset the Terran "Lytham"), I got 1,096 new words.
Along the way I passed word #103,000, which was Srentshaithrang (Srenchaithrang, a city in the Sengtan Mountains, created to offset "Luoyang").
Nice to be halfway throigh the English language with this big list!
Along the way I passed word #103,000, which was Srentshaithrang (Srenchaithrang, a city in the Sengtan Mountains, created to offset "Luoyang").
Nice to be halfway throigh the English language with this big list!
♂♥♂♀
Squirrels chase koi . . . chase squirrels
My Kankonian-English dictionary: Now at 113,000 words!
31,416: The number of the conlanging beast!
Squirrels chase koi . . . chase squirrels
My Kankonian-English dictionary: Now at 113,000 words!
31,416: The number of the conlanging beast!
Re: What did you accomplish today?
Thank you for the feedback. The system I currently have implemented is a simplified version of what you suggest: it concatenates year, month, day and a randomly generated 4-digit number (with the randomiser seeded at launch time). Using information from the system is a good idea though, and I should probably add hours and minutes for safety.eldin raigmore wrote: ↑21 Oct 2024 01:38
You can guarantee uniqueness by using a UTC timestamp plus a language-counter plus a code uniquely identifying the creator and/or the computer from which the creating was done. 32 bits probably won’t be enough to guarantee uniqueness, but I bet 128 will be. (If not, surely 256 bits will be enough?)
The time probably doesn’t need to be preciser than 1 second, but you might want to use .01 sec instead.
The language-counter probably can recycle itself every million (10^6) times, but you may prefer a billion (10^9) times.
I think at max that might use:
105 bits for time-created
32 bits for creator id
32 bits for computer id
30 bits for number of languages created in this centi-second
________.
199 bits.
That’s probably overkill.
——————.
I like the problems and solutions you come up with!
I will keep lurking!
It's somewhat questionable how much of a safety margin will be necessary though, since in most cases users will probably only work with their own data. With a date-based ID, the risk of overwrite would probably only come into play if 1) users have access to a file created by someone else 2) and they import data of that file into another project 3) and both the target and source files have a node of the exact same type (e.g. a language node) with the exact same ID, which requires them to have been created the same day and somehow have been tagged with the exact same randomly generated number.
The only other scenario I could imagine is if the randomiser managed to generate the same number twice on the same day while tagging the same kind of node. How likely that is, I'm not sure.
DeviantArt | YouTube | Tumblr
Re: What did you accomplish today?
I'm adding a vocative case to Mariupol Gothic.
For feminine nouns this means just replacing /ə/ in the noun with /o/, not too unlike Romanian. Hence I have минэ /miːnə/ "moon" becoming мино /miːno/ "O moon!" For masculine nouns I'm thinking it'll be /a/ instead.
For feminine nouns this means just replacing /ə/ in the noun with /o/, not too unlike Romanian. Hence I have минэ /miːnə/ "moon" becoming мино /miːno/ "O moon!" For masculine nouns I'm thinking it'll be /a/ instead.
Мин атэнс а̄т адэ
My father's eight eggs
- Crimean Gothic tongue twister
A-posteriori, alternative history nerd
My father's eight eggs
- Crimean Gothic tongue twister
A-posteriori, alternative history nerd
Re: What did you accomplish today?
So, among other things, I decided to implement a similar "generative ID" system for the storage of phonological transcription systems, because I felt that they as well might be subject to accidental overwriting. Until then, they were stored by name.
Which might have turned out to be unnecessarily cautious on my part. Not unnecessary as a safety measure per se, but unnecessary because it gave me (and still gives me) a lot of work that I didn't fully expect and that I wish I didn't have. But oh well, what's done is done.
At least it motivated me to rewrite from scratch the mechanism which displays all units in the system on the editing sheet, because the previous mechanism was one of the oldest parts of my project and thus woefully outdated. The new one is probably only a third as long and much more readable. Between that, and the fact that it implements a lot of things that I've learned since writing the old one, it'll be much easier to maintain and modify in the future.
I'm not looking forward to a bunch of other bugs I expect to discover as a result of switching to the ID system, though. And I regret that it will make the project storage file less human-readable as well (it takes the form of a JSON file, which is extremely easy to parse and modify manually if needed), since every mention of a phonological transcription system would be replaced by the ID, e.g. in a section describing a sound change.
So, what I'm pondering right now is to maybe make the ID internal and use the name as the main referent, in order to preserve that readability.
Which might have turned out to be unnecessarily cautious on my part. Not unnecessary as a safety measure per se, but unnecessary because it gave me (and still gives me) a lot of work that I didn't fully expect and that I wish I didn't have. But oh well, what's done is done.
At least it motivated me to rewrite from scratch the mechanism which displays all units in the system on the editing sheet, because the previous mechanism was one of the oldest parts of my project and thus woefully outdated. The new one is probably only a third as long and much more readable. Between that, and the fact that it implements a lot of things that I've learned since writing the old one, it'll be much easier to maintain and modify in the future.
I'm not looking forward to a bunch of other bugs I expect to discover as a result of switching to the ID system, though. And I regret that it will make the project storage file less human-readable as well (it takes the form of a JSON file, which is extremely easy to parse and modify manually if needed), since every mention of a phonological transcription system would be replaced by the ID, e.g. in a section describing a sound change.
So, what I'm pondering right now is to maybe make the ID internal and use the name as the main referent, in order to preserve that readability.
DeviantArt | YouTube | Tumblr
Re: What did you accomplish today?
After hunting down and fixing a bunch of bugs, then implementing some stuff I noticed I hadn't in the process, I've finally gotten back to working on my diachronic conlanging app's "language phonology editor", specifically the inventory and phoneme editors.
You can now add units from any transcription system as a phoneme to the inventory of a chosen language. A separate "phoneme editor" tool will display all information about the phoneme upon selection (i.e. symbol, unicode equivalent, phonological system, and a grid of features and the feature sets they belong to); and allow the addition of language-specific notes and tags to each phoneme.
Next up, I'll adapt the widget to also display information about units not yet added, and next I'll probably work on an inventory display system where users can create their own charts. I'm curious as to how difficult or easy that will turn out to be.
You can now add units from any transcription system as a phoneme to the inventory of a chosen language. A separate "phoneme editor" tool will display all information about the phoneme upon selection (i.e. symbol, unicode equivalent, phonological system, and a grid of features and the feature sets they belong to); and allow the addition of language-specific notes and tags to each phoneme.
Next up, I'll adapt the widget to also display information about units not yet added, and next I'll probably work on an inventory display system where users can create their own charts. I'm curious as to how difficult or easy that will turn out to be.
DeviantArt | YouTube | Tumblr
-
Creyeditor

- MVP

- Posts: 5405
- Joined: 14 Aug 2012 19:32
- Contact:
Re: What did you accomplish today?
I added sample sentences for Omlueuet and Kobardon to my website.
Creyeditor
https://sites.google.com/site/creyeditor/
Produce, Analyze, Manipulate
1 2
2  3
3  4
4  4
4 
 Omlűt & Kobardon & Fredauon Fun Facts & AMA on Indonesian
Omlűt & Kobardon & Fredauon Fun Facts & AMA on Indonesian
![[<3]](./images/smilies/heartic.png "<3") Papuan languages, Morphophonology, Lexical Semantics
Papuan languages, Morphophonology, Lexical Semantics
https://sites.google.com/site/creyeditor/
Produce, Analyze, Manipulate
1

Re: What did you accomplish today?
Where is your website?Creyeditor wrote: ↑02 Nov 2024 03:25 I added sample sentences for Omlueuet and Kobardon to my website.
My meta-thread: viewtopic.php?f=6&t=5760
-
Creyeditor
- MVP
- Posts: 5405
- Joined: 14 Aug 2012 19:32
- Contact:
Re: What did you accomplish today?
I thought it already was in my signature. Turns out it wasn't. So here it is: https://sites.google.com/site/creyeditor/.
Edit: Updated my signature.
Edit: Hopefully fixed the Indonesian conlang bug.
Last edited by Creyeditor on 03 Nov 2024 07:22, edited 1 time in total.
Creyeditor
https://sites.google.com/site/creyeditor/
Produce, Analyze, Manipulate
1 2 3 4 4
Omlűt & Kobardon & Fredauon Fun Facts & AMA on Indonesian
Papuan languages, Morphophonology, Lexical Semantics
https://sites.google.com/site/creyeditor/
Produce, Analyze, Manipulate
1
-
VaptuantaDoi

- roman

- Posts: 1347
- Joined: 18 Nov 2019 07:35
Re: What did you accomplish today?
Your sig does seem to imply that Indonesian is a conlang.Creyeditor wrote: ↑03 Nov 2024 02:17 I thought it already was in my signature. Turns out it wasn't. So here it is: https://sites.google.com/site/creyeditor/.Edit: Updated my signature.
-
Creyeditor
- MVP
- Posts: 5405
- Joined: 14 Aug 2012 19:32
- Contact:
Re: What did you accomplish today?
I added Mamabam (with sample sentences) to my website. (I'm planning to add more languages, such as K'uk'uts' and sample sentences for the other languages.) I also decided that the sapient Water Bears on Fredauon will not have language in any way that humans can recognize. They will show stuff and might point to it whwn trying to communicate with humans and they will use posture and the like to communicate with each other. This contrasts with the sapient avian Hoatzyn, which have some kind of language-like communication.
Creyeditor
https://sites.google.com/site/creyeditor/
Produce, Analyze, Manipulate
1 2 3 4 4
Omlűt & Kobardon & Fredauon Fun Facts & AMA on Indonesian
Papuan languages, Morphophonology, Lexical Semantics
https://sites.google.com/site/creyeditor/
Produce, Analyze, Manipulate
1
-
KaiTheHomoSapien

- greek

- Posts: 666
- Joined: 15 Feb 2016 06:10
- Location: Northern California
Re: What did you accomplish today?
So I've been trying to come up with a conlang that isn't IE-like, like all my extant conlangs are to date, but it's hard. It keeps veering into IE-territory. And I'm just talking about phonology here. Meh, I like what I like.
That said, I've come up with enough material that I may post it soon. It's not perfectly IE-free, but maybe it doesn't have to be.
That said, I've come up with enough material that I may post it soon. It's not perfectly IE-free, but maybe it doesn't have to be.

Re: What did you accomplish today?
My diachronic conlanging tool finally has the bare-bones mechanism to sort a language's inventory into a grid. It's pretty basic and still wants refining as well as proper implementation, but it's there and it works. I spent a while dealing with other issues, and then racking my brain over how to implement it. The basic idea of filtering for features isn't complicated, but I wanted to leave some doors open for other methods - and accounting for that kind of polyvalence makes things a whole lot more difficult.
But I think I have something that does the basic stuff most people need, and if down the line someone needs to create a single hexadimensional grid to sort phonemes across three unrelated phonological transcription systems, I might just be able to implement that.
But I think I have something that does the basic stuff most people need, and if down the line someone needs to create a single hexadimensional grid to sort phonemes across three unrelated phonological transcription systems, I might just be able to implement that.
DeviantArt | YouTube | Tumblr
Re: What did you accomplish today?
I've ported my Commonthroat lexicon from Excel to Obsidian. This should allow for much richer and deeper documentation, more closely mirroring the lore-heavy lexeme posts I make in the CT thread here. I've also changed the romanization again, this time to avoid the use of capitals. The lexicon now uses combining macrons over long vowels, but I'll probably still use the second, case-sensitive, Romanization on the forum (the first one was the one with vowel letters).
-
Creyeditor
- MVP
- Posts: 5405
- Joined: 14 Aug 2012 19:32
- Contact:
Re: What did you accomplish today?
I finished my preliminary taxonomy of mammals on Fredauon and started with the bird taxonomy (much more genera than I was expecting).
Creyeditor
https://sites.google.com/site/creyeditor/
Produce, Analyze, Manipulate
1 2 3 4 4
Omlűt & Kobardon & Fredauon Fun Facts & AMA on Indonesian
Papuan languages, Morphophonology, Lexical Semantics
https://sites.google.com/site/creyeditor/
Produce, Analyze, Manipulate
1
-
WeepingElf

- greek
- Posts: 710
- Joined: 23 Feb 2016 18:42
- Location: Braunschweig, Germany
- Contact:
Re: What did you accomplish today?
I sometimes have my best ideas late at night, so again this time. I got up and jotted it down. So here it is:
I have found out how PIE ablaut and vowel autosegmentality interplay in Old Albic. Vowel features are connected to morphemes, and the vowels are inserted into the consonant string by phonotactic rules. There are two sources of vowel features: ablaut grades, and semivowels and laryngeals. There are four vowel features, three qualitative and one quantitative: [+open], [+front], [+round] and [+long]. They can combine freely, though I don't know yet whether all combinations actually occur.
The vowel features provided by the ablaut grades are thus:
Zero grade: none
A-grade (< PIE o-grade): [+open]
I-grade (< PIE e-grade): [+front]
Â-grade (< PIE ô-grade): [+open][+long]
Î-grade (< PIE ê-grade): [+front][+long]
Syllabic semivowels also contribute:
*i: [+front]
*u: [+round]
Laryngeals: none
Post-vocalic semivowels the same, plus [+long]
Vowel positions in morphemes without vowel features attached borrow their features from the nearest vowel with features. In a final step, [+long] is deleted in unstressed vowels and in vowels in closed syllables except in monosyllables.
Let's see how this works in practice.
Consider the Old Albic word for 'father', in the agentive singular. The consonant string is ph3-tr-h, and the ablaut grades of the three morphemes are 0-i-0. Thus, the second morpheme carries the vowel feature [+front], while the first and the third morpheme carry none. The resulting word form is phitiri.
The dative singular consists of the consonant string ph3-tr-i with the ablaut grades 0-0-i. So the last morpheme carries [+front] (actually twice, one from the i-grade, and one from the semivowel, but twice the same feature equals once the feature), while the first two morphemes carry no features. This results in he form phitri.
There is also a derivative of this word, the word for 'teacher', which is the consonant string ph3-tr-3n-h and the ablaut grades 0-0-a-0. The laryngeal in the third morpheme contributes [+long], so the result is phatrána.
All this is of course just work in progress, and may be modified later.
I have found out how PIE ablaut and vowel autosegmentality interplay in Old Albic. Vowel features are connected to morphemes, and the vowels are inserted into the consonant string by phonotactic rules. There are two sources of vowel features: ablaut grades, and semivowels and laryngeals. There are four vowel features, three qualitative and one quantitative: [+open], [+front], [+round] and [+long]. They can combine freely, though I don't know yet whether all combinations actually occur.
The vowel features provided by the ablaut grades are thus:
Zero grade: none
A-grade (< PIE o-grade): [+open]
I-grade (< PIE e-grade): [+front]
Â-grade (< PIE ô-grade): [+open][+long]
Î-grade (< PIE ê-grade): [+front][+long]
Syllabic semivowels also contribute:
*i: [+front]
*u: [+round]
Laryngeals: none
Post-vocalic semivowels the same, plus [+long]
Vowel positions in morphemes without vowel features attached borrow their features from the nearest vowel with features. In a final step, [+long] is deleted in unstressed vowels and in vowels in closed syllables except in monosyllables.
Let's see how this works in practice.
Consider the Old Albic word for 'father', in the agentive singular. The consonant string is ph3-tr-h, and the ablaut grades of the three morphemes are 0-i-0. Thus, the second morpheme carries the vowel feature [+front], while the first and the third morpheme carry none. The resulting word form is phitiri.
The dative singular consists of the consonant string ph3-tr-i with the ablaut grades 0-0-i. So the last morpheme carries [+front] (actually twice, one from the i-grade, and one from the semivowel, but twice the same feature equals once the feature), while the first two morphemes carry no features. This results in he form phitri.
There is also a derivative of this word, the word for 'teacher', which is the consonant string ph3-tr-3n-h and the ablaut grades 0-0-a-0. The laryngeal in the third morpheme contributes [+long], so the result is phatrána.
All this is of course just work in progress, and may be modified later.
Re: What did you accomplish today?
Uuuuugh. Took me long enough, much longer than I would have liked, no less because I ran into a bunch of unexpected bugs and difficulties, but it's finally done: I have a basic, functional mechanism for users to create custom grids to display the inventories of their language in a familiar, easy-to-parse manner.
There's plenty of things left to implement, such as changing the order of grids in the layout, making auto-hiding of empty rows/columns optional, etc...; and plenty of room for more advanced (read: headache-inducing) features, but the basic thing works. Finally.
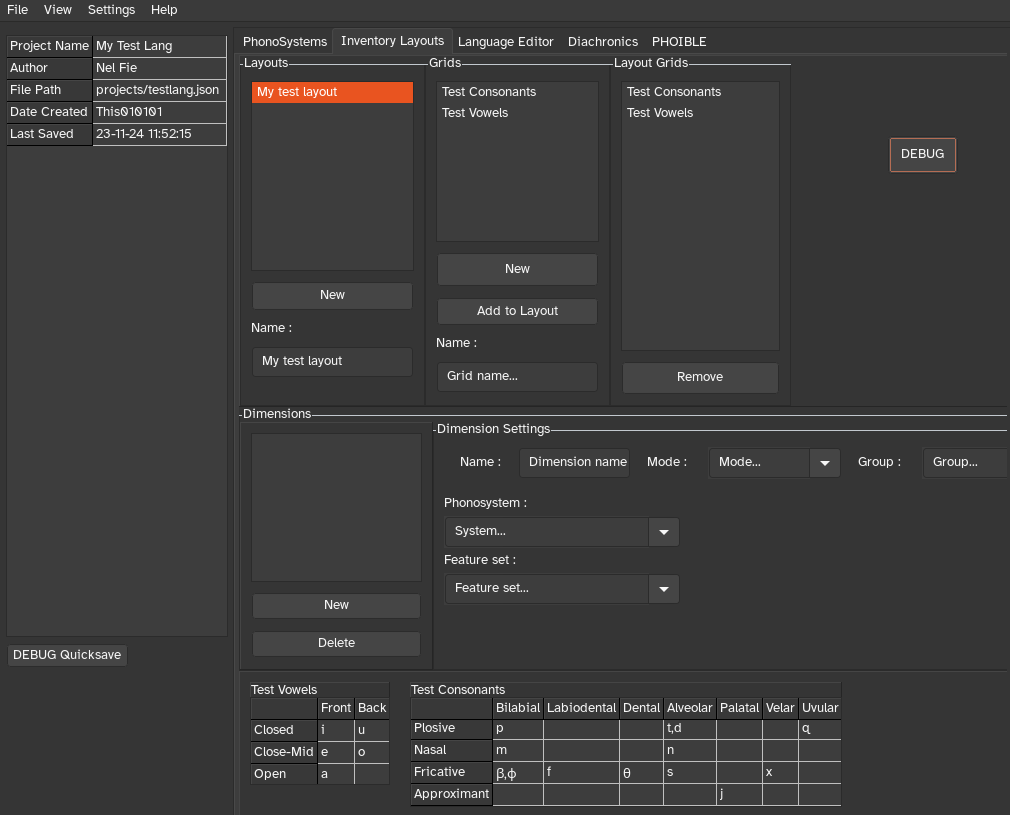
There's plenty of things left to implement, such as changing the order of grids in the layout, making auto-hiding of empty rows/columns optional, etc...; and plenty of room for more advanced (read: headache-inducing) features, but the basic thing works. Finally.
DeviantArt | YouTube | Tumblr
Re: What did you accomplish today?
I finally put my comprehensive Commonthroat grammar up on Frathwiki https://www.frathwiki.com/Commonthroat
The excessive use of code blocks is to achieve a common denominator between all the formats I want to port the document to. Tables are surprisingly finicky. You can't even do tables in PHPBB. I need to see how accessible it is to a braille display at some point.
The excessive use of code blocks is to achieve a common denominator between all the formats I want to port the document to. Tables are surprisingly finicky. You can't even do tables in PHPBB. I need to see how accessible it is to a braille display at some point.